Global symposium on AI & Inclusion in beautiful Rio de Janeiro

The Museum of Tomorrow
Last week, I had the immense pleasure of participating in the Global AI & Inclusion Symposium at the Museum of Tomorrow in Rio de Janeiro, Brazil. The Global Network of Internet & Society Centers (NoC) invited a wide range of stakeholders toRio during November 8-10, 2017. Spearheaded and organized by the Berkman Klein Center for Internet and Society at Harvard University and the Institute of Technology and Society in Rio, the symposium brought together researchers, industry, NGOs, and other entities to discuss issues around inclusion and artificial intelligence (AI).
One of the key aspects of this symposium was the inclusion of perspectives fromnot only a wide range of areas and disciplines, but also from all regions across the globe. Each region was represented—however, more inclusion of underrepresented areas was noted as an area of action for future activities, as the discourse still saw a larger number of perspectives from Western backgrounds. As an example, although China is one of the key players regarding AI, only a small number of representatives were from China or provided a background on AI and inclusion in China.
The symposium was jam-packed with high-caliber talks, discussions, and activities. The symposium program can be found here. Whereas the first day focused on creating a common understanding of AI and inclusion as concepts and frameworks, the second day identified opportunities, challenges, and possible approaches and solutions to increase inclusion in AI, and the third day focused on areas for future research, education and interface building.
All speakers provided impressive background and knowledge on AI and inclusion to a multidisciplinary and multifaceted audience, which created a steep learning curve for me as a social scientist with (previously) little background in the technologies behind AI. However, the design of the symposium talks and activities facilitated a deep understanding of the issues around AI and inclusion for individuals from any disciplinary background.
Key issues in AI and inclusion
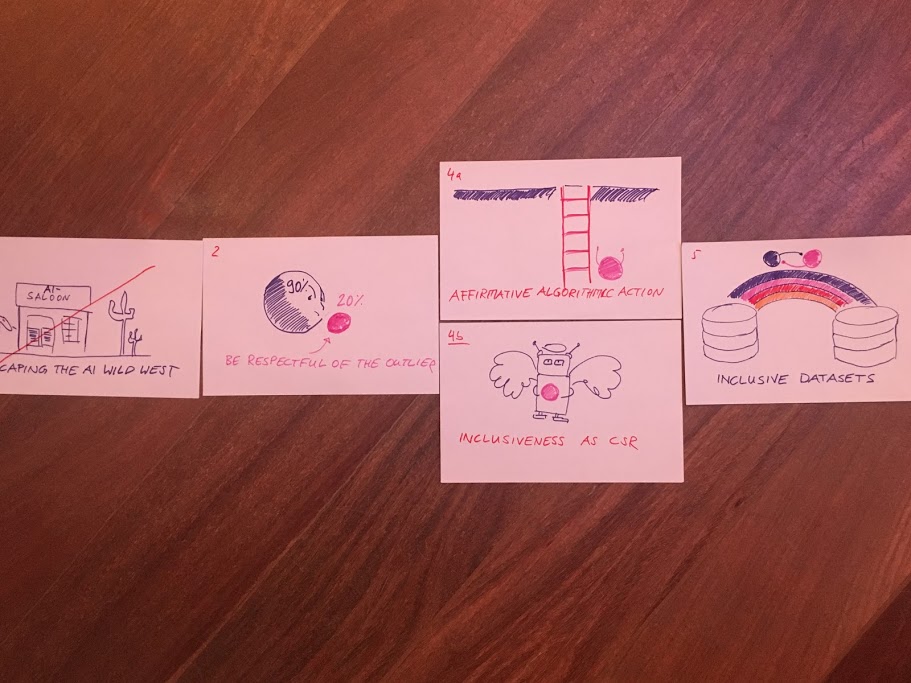
Our cluster group’s suggestion on how to escape the AI Wild West and move toward unbiased (or less biased at least) AI
One of the key issues that stood out at this symposium is the bias and the exclusionary nature of AI through the way that AI is created and trained. For example, algorithms, which are an inherent part of AI, that are created through training datasets are only as good as those datasets. This means, if a training dataset—created by a human—is biased, the algorithm will be biased too. This became apparent quickly through a variety of examples, that included work from Desabafo Social, a non-profit that promotes social justice and youth participation in Brazil, which showed videos that revealed racist bias in search algorithms for a variety of photo sharing pages. An impressive example of their enlightening videos can be found here.
These issues of bias and exclusion at the creation stage do not just include race as a factor, but any underrepresented group. For example, the technology created for airport security prompts the security agents to choose whether a person is male or female before entering the millimeter wave scanner. Based on training datasets of typical male and female bodies, the scanner then decides whether there could be any objects hidden on those bodies. However, this AI technology (Automatic Target Recognition, ATR) only differentiates two genders, meaning that anyone who does not fall into these two categories will be marked as suspicious and will have to go through a secondary security hand search.
Another striking takeaway from the conference was the missing legal definition of AI and the absence of global standards in AI. For example, AI accuracy in face recognition is very high for white males, but low for black females. A good practice standard, for example a minimum accuracy requirement, does not currently exist, although a number of entities, such as the Mozilla Foundation, are aiming to create such standards as a “fair AI” badge—similar to the fair-trade badge—to remedy these issues.
Another area of concern in AI is privacy and surveillance, as AI relies on copious amounts of data to learn and improve its algorithms. However, users are often unsure of when, where, and how their data are collected and used for which purposes. Although some regulations have been passed to protect users’ privacy, these regulations are not global, and different regions apply different laws and regulations. Accordingly, there were calls for—first of all—a global legal definition of AI, which

The Berkman Klein and ITS Rio team who organized the symposium
would provide the basis for creating global regulations on inclusion, privacy, and other areas affected by AI. Again, the Mozilla Foundation made a number of suggestions on “fair AI” and they provide a “holiday buyer’s guide” on technology that will “snoop” on you—i.e., presents that you should probably not give to your loved ones… unless you’d like them to be snooped on…
Future Event on AI, bias, and inclusion at the Quello Center
Overall, the symposium left me personally with more questions than answers, but I am consoled by the fact that every single participant I spoke with felt invigorated and motivated to do something to move forward the cause of increasing inclusion in AI. For one, we all agreed to help make these issues a public conversation topic—this blog post is only the start. At the Quello Center, I will be organizing a discussion roundtable concerning issues around artificial intelligence, bias, and social exclusion, that will delve deeper into these issues based on the work that is happening here at MSU. Watch this space for a time and date during the spring semester 2018.